Edvancer's Knowledge Hub
Anatomy of a data science project
Before the cool algorithms and complex data architectures, comes the process that all data science projects must follow (I know this already sounds a little bookish, but trust me – I am just breaking the subject down into little pieces!).
Different projects follow different approaches, but the objective remains largely the same – let the data give you inputs and present the insights learned in an appealing and understandable way to the client.
An incremental approach (similar to agile model) as opposed to a waterfall development model can save time, effort, and money. Deriving continuous value from the data in each cycle is safer and quicker. It is because this approach allows us to get actionable insights and be better prepared to apply operations on the data with every iteration.
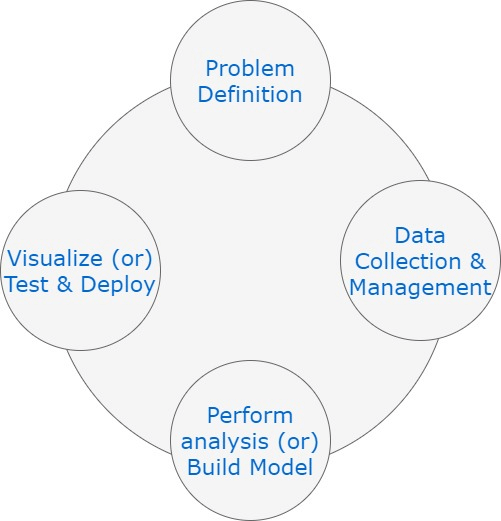
If we were to club some of the sub-tasks and broadly present the stages of a datascience project, this is what it would look like:
 Problem definition
It involves asking relevant questions and completely nailing down the business use case. Some of those questions could be:
Problem definition
It involves asking relevant questions and completely nailing down the business use case. Some of those questions could be:

Share this on
Follow us on
 Problem definition
It involves asking relevant questions and completely nailing down the business use case. Some of those questions could be:
Problem definition
It involves asking relevant questions and completely nailing down the business use case. Some of those questions could be:
- What is the ultimate objective of the project? Is it to optimize ad spend during the holidays or to build a system capable of changing air conditioning settings to match the number of customers in the store?
- Will Data Science really add value and why is it needed? The team and the client both have to believe that there is a need for using machine learning algorithms or analytics techniques to get insights or build a system.
- What are the data sources? Will they be given to the team by the client or will the team have to find it from public sources?
Manu Jeevan
Manu Jeevan is a self-taught data scientist and loves to explain data science concepts in simple terms. You can connect with him on LinkedIn, or email him at manu@bigdataexaminer.com.
Latest posts by Manu Jeevan (see all)
- Python IDEs for Data Science: Top 5 - January 19, 2019
- The 5 exciting machine learning, data science and big data trends for 2019 - January 19, 2019
- A/B Testing Made Simple – Part 2 - October 30, 2018
Follow us on
Free Data Science & AI Starter Course
