Edvancer's Knowledge Hub
How is machine learning different from AI and data science?

In this blog post, I will explain how machine learning fits into the broader landscape of data and computer science. This means understanding how machine learning interrelates with parent fields and sister disciplines. This is important, as these are the terms you will see time and again when searching for relevant study materials and hear mentioned ad nauseam in machine learning books. Relevant disciplines can also be difficult and confusing to tell apart at first glance, such as ‘machine learning’ and ‘data mining.’ The lineage of machine learning can be understood by first examining its forefathers.
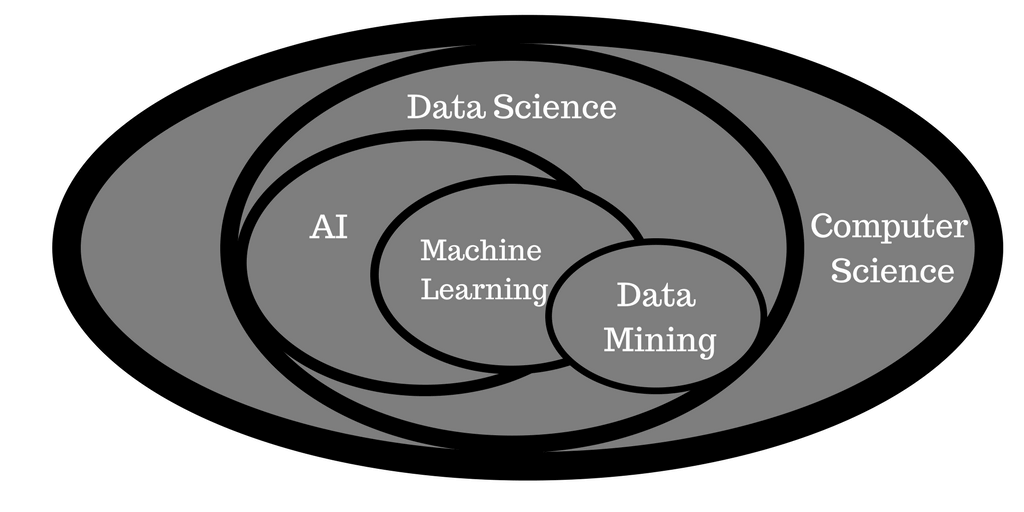
Machine learning derives first from computer science.
Computer science encompasses everything interrelated to the design and use of computers. Within the all-encompassing space of computer science is the next broad field of data science. Narrower than computer science, data science comprises methods and systems to extract knowledge and insights from data through the use of computers.
Popping out from computer science and data science is artificial intelligence. Artificial intelligence, or AI, encompasses the ability of machines to perform intellectual and cognitive tasks. Comparable to the way the Industrial Revolution gave birth to machines that could simulate physical activities, AI is now driving the development of machines capable of simulating cognitive tasks. While still broad but dramatically more honed than computer science and data science, AI contains numerous subfields that are popular today. These subfields include search and planning, reasoning and knowledge representation, perception, natural language processing (NLP), and of course, machine learning.
Machine learning bleeds into other fields of AI, including NLP and perception through the shared use of self-learning algorithms. For people with an interest in AI, machine learning provides an excellent starting point. Given the conceptual ambiguity of AI, machine learning offers a narrow and practical domain of study. Algorithms taught in machine learning can be applied across other disciplines, including perception and natural language processing.
 Machine learning also overlaps with data mining
Data mining is a sister discipline that focuses on discovering and unearthing patterns in large datasets.
Popular self-learning algorithms such as k-means clustering, association analysis, and regression analysis are used in both data mining and machine learning to analyze data. But where machine learning focuses on the incremental process of self-learning, data mining narrows its efforts on cleaning up large datasets to uncover valuable new insight.
The difference between data mining and machine learning can be explained through an analogy to two teams of archaeologists.
The first team of archaeologists focus on removing debris that lies in the way of valuable items hidden from sight. The team’s primary goal is to excavate the area, find new valuable discoveries, and then pack up their equipment and leave. A day later, they will fly to another exotic destination and start a new project with no correlation to the site they excavated the day before.
The second team is also in the business of excavating historical sites but their approach is different. They hold off from excavating the main pit for many weeks. In that time, they visit other relevant archaeological sites in the region and examine how each site was excavated. After returning to the site of their own project, they apply this knowledge to excavate smaller pits surrounding the main pit. The archaeologists then analyze the results. After reflecting on their experience excavating one pit, they improve their efforts at tackling the next. This includes predicting the amount of time it takes to excavate the pit, understanding variance and patterns found in the local terrain and developing new strategies to improve the accuracy of their work. From this experience, they are able to optimize their approach to form a strategic model that they will implement to excavate the main pit.
If it is not already clear, the first team subscribes to data mining and the second team to machine learning. At a micro-level, both data mining and machine learning appear similar and use many of the same tools. Both teams make a living excavating historical sites to discover valuable items. But in practice, their methodology is different. The machine learning team focus on self-learning and improving future predictions based on previous experience. Meanwhile, the data mining team concentrate on excavating the target area as effectively as possible before moving on to the next clean-up job.
Machine learning also overlaps with data mining
Data mining is a sister discipline that focuses on discovering and unearthing patterns in large datasets.
Popular self-learning algorithms such as k-means clustering, association analysis, and regression analysis are used in both data mining and machine learning to analyze data. But where machine learning focuses on the incremental process of self-learning, data mining narrows its efforts on cleaning up large datasets to uncover valuable new insight.
The difference between data mining and machine learning can be explained through an analogy to two teams of archaeologists.
The first team of archaeologists focus on removing debris that lies in the way of valuable items hidden from sight. The team’s primary goal is to excavate the area, find new valuable discoveries, and then pack up their equipment and leave. A day later, they will fly to another exotic destination and start a new project with no correlation to the site they excavated the day before.
The second team is also in the business of excavating historical sites but their approach is different. They hold off from excavating the main pit for many weeks. In that time, they visit other relevant archaeological sites in the region and examine how each site was excavated. After returning to the site of their own project, they apply this knowledge to excavate smaller pits surrounding the main pit. The archaeologists then analyze the results. After reflecting on their experience excavating one pit, they improve their efforts at tackling the next. This includes predicting the amount of time it takes to excavate the pit, understanding variance and patterns found in the local terrain and developing new strategies to improve the accuracy of their work. From this experience, they are able to optimize their approach to form a strategic model that they will implement to excavate the main pit.
If it is not already clear, the first team subscribes to data mining and the second team to machine learning. At a micro-level, both data mining and machine learning appear similar and use many of the same tools. Both teams make a living excavating historical sites to discover valuable items. But in practice, their methodology is different. The machine learning team focus on self-learning and improving future predictions based on previous experience. Meanwhile, the data mining team concentrate on excavating the target area as effectively as possible before moving on to the next clean-up job.

Share this on
Follow us on
 Machine learning also overlaps with data mining
Data mining is a sister discipline that focuses on discovering and unearthing patterns in large datasets.
Popular self-learning algorithms such as k-means clustering, association analysis, and regression analysis are used in both data mining and machine learning to analyze data. But where machine learning focuses on the incremental process of self-learning, data mining narrows its efforts on cleaning up large datasets to uncover valuable new insight.
The difference between data mining and machine learning can be explained through an analogy to two teams of archaeologists.
The first team of archaeologists focus on removing debris that lies in the way of valuable items hidden from sight. The team’s primary goal is to excavate the area, find new valuable discoveries, and then pack up their equipment and leave. A day later, they will fly to another exotic destination and start a new project with no correlation to the site they excavated the day before.
The second team is also in the business of excavating historical sites but their approach is different. They hold off from excavating the main pit for many weeks. In that time, they visit other relevant archaeological sites in the region and examine how each site was excavated. After returning to the site of their own project, they apply this knowledge to excavate smaller pits surrounding the main pit. The archaeologists then analyze the results. After reflecting on their experience excavating one pit, they improve their efforts at tackling the next. This includes predicting the amount of time it takes to excavate the pit, understanding variance and patterns found in the local terrain and developing new strategies to improve the accuracy of their work. From this experience, they are able to optimize their approach to form a strategic model that they will implement to excavate the main pit.
If it is not already clear, the first team subscribes to data mining and the second team to machine learning. At a micro-level, both data mining and machine learning appear similar and use many of the same tools. Both teams make a living excavating historical sites to discover valuable items. But in practice, their methodology is different. The machine learning team focus on self-learning and improving future predictions based on previous experience. Meanwhile, the data mining team concentrate on excavating the target area as effectively as possible before moving on to the next clean-up job.
Machine learning also overlaps with data mining
Data mining is a sister discipline that focuses on discovering and unearthing patterns in large datasets.
Popular self-learning algorithms such as k-means clustering, association analysis, and regression analysis are used in both data mining and machine learning to analyze data. But where machine learning focuses on the incremental process of self-learning, data mining narrows its efforts on cleaning up large datasets to uncover valuable new insight.
The difference between data mining and machine learning can be explained through an analogy to two teams of archaeologists.
The first team of archaeologists focus on removing debris that lies in the way of valuable items hidden from sight. The team’s primary goal is to excavate the area, find new valuable discoveries, and then pack up their equipment and leave. A day later, they will fly to another exotic destination and start a new project with no correlation to the site they excavated the day before.
The second team is also in the business of excavating historical sites but their approach is different. They hold off from excavating the main pit for many weeks. In that time, they visit other relevant archaeological sites in the region and examine how each site was excavated. After returning to the site of their own project, they apply this knowledge to excavate smaller pits surrounding the main pit. The archaeologists then analyze the results. After reflecting on their experience excavating one pit, they improve their efforts at tackling the next. This includes predicting the amount of time it takes to excavate the pit, understanding variance and patterns found in the local terrain and developing new strategies to improve the accuracy of their work. From this experience, they are able to optimize their approach to form a strategic model that they will implement to excavate the main pit.
If it is not already clear, the first team subscribes to data mining and the second team to machine learning. At a micro-level, both data mining and machine learning appear similar and use many of the same tools. Both teams make a living excavating historical sites to discover valuable items. But in practice, their methodology is different. The machine learning team focus on self-learning and improving future predictions based on previous experience. Meanwhile, the data mining team concentrate on excavating the target area as effectively as possible before moving on to the next clean-up job.
Manu Jeevan
Manu Jeevan is a self-taught data scientist and loves to explain data science concepts in simple terms. You can connect with him on LinkedIn, or email him at manu@bigdataexaminer.com.
Latest posts by Manu Jeevan (see all)
- Python IDEs for Data Science: Top 5 - January 19, 2019
- The 5 exciting machine learning, data science and big data trends for 2019 - January 19, 2019
- A/B Testing Made Simple – Part 2 - October 30, 2018
Follow us on
Free Data Science & AI Starter Course
