Edvancer's Knowledge Hub
An introduction to Hadoop and its ecosystem

When someone mentions Hadoop, they generally don’t refer to the core Apache Hadoop project, but instead are referring to its technology along with an ecosystem of other projects that work with Hadoop. It’s just like when someone tells you they are using Linux as their operating system but they mean the thousands of applications that run on the Linux kernel along with it.
Core Apache Hadoop
Core Hadoop is a software platform and framework for distributed computing of data. Hadoop is a long-running system that runs and executes computing tasks akin to a platform. Platforms make it easier for engineers to deploy applications and analytics because they don’t have to work on building the infrastructure from scratch for every task again. Hadoop is a framework in the sense that it provides a layer of abstraction to developers of data applications and data analytics that keeps the intricacies of the system hidden. The core Apache Hadoop project is organized into three major components that provide a foundation for the rest of the ecosystem:
 Source: data science central
Hadoop and its ecosystem represent a new way of doing things, as we’ll look at next.
Hadoop Masks Being a Distributed System
Hadoop is a distributed system, which means it coordinates the usage of a cluster of multiple computational resources (referred to as servers, computers, or nodes) that communicate over a network. Using distributed systems we can solve problems that cannot be solved by a single computer. A distributed system can store more data than can be stored on just one machine and process data much faster than a single machine can. However, this increases complexity, because the computers in the cluster need to communicate with each other, and the system needs to handle the increased chance of failure inherent in using more machines.
These are some of the disadvantages of using a distributed system. We don’t use distributed systems because we want to…we use them because we cannot do without them.
Hadoop does a good job of hiding from its users that it is a distributed system by portraying itself as a single system. This makes the life of the user a whole lot easier because he or she can focus on analysis of data part instead of manually coordinating different computers or manually planning for failures.
Take a look at this snippet of Hadoop MapReduce code written in Java. Even if you aren’t well versed with Java, you can still look at the code and get a general feel of what’s happening. There is a point to this, I promise.
Here’s an example MapReduce job that I wrote in Java to count words.
// This block of code defines the behavior of the map phase
// This block of code defines the behavior of the reducer phase
This code is for word counting, the canonical example for MapReduce. MapReduce can do all sorts of fancy things, but in this relatively simple case it takes a body of text, and it will return the list of words seen in the text along with how many times each of those words was seen.
Nowhere in the code is there a mention of how much data is being analyzed or what the size of the cluster is. . The code in the above example could be run over a 10,000 node Hadoop cluster or on a laptop without any modifications. This same code could process 20 petabytes of website text or could process a single email.
This makes the code extremely portable, which means that before shipping it can be tested on a developer’s workstation with a sample of data. The code does not need to be changed if the nature or size of the cluster changes later down the road. Also, this abstracts away all of the complexities of a distributed system for the developer, which makes his or her life easier in several ways: opportunities to make errors are reduced, fault tolerance is built in, there is lesser code to write, and so much more — in short.
Hadoop has taken off in terms of popularity owing to its accessibility to the average software developer in comparison to previous distributed computing frameworks is one of the main reasons why Hadoop has taken off in terms of popularity.
Source: data science central
Hadoop and its ecosystem represent a new way of doing things, as we’ll look at next.
Hadoop Masks Being a Distributed System
Hadoop is a distributed system, which means it coordinates the usage of a cluster of multiple computational resources (referred to as servers, computers, or nodes) that communicate over a network. Using distributed systems we can solve problems that cannot be solved by a single computer. A distributed system can store more data than can be stored on just one machine and process data much faster than a single machine can. However, this increases complexity, because the computers in the cluster need to communicate with each other, and the system needs to handle the increased chance of failure inherent in using more machines.
These are some of the disadvantages of using a distributed system. We don’t use distributed systems because we want to…we use them because we cannot do without them.
Hadoop does a good job of hiding from its users that it is a distributed system by portraying itself as a single system. This makes the life of the user a whole lot easier because he or she can focus on analysis of data part instead of manually coordinating different computers or manually planning for failures.
Take a look at this snippet of Hadoop MapReduce code written in Java. Even if you aren’t well versed with Java, you can still look at the code and get a general feel of what’s happening. There is a point to this, I promise.
Here’s an example MapReduce job that I wrote in Java to count words.
// This block of code defines the behavior of the map phase
// This block of code defines the behavior of the reducer phase
This code is for word counting, the canonical example for MapReduce. MapReduce can do all sorts of fancy things, but in this relatively simple case it takes a body of text, and it will return the list of words seen in the text along with how many times each of those words was seen.
Nowhere in the code is there a mention of how much data is being analyzed or what the size of the cluster is. . The code in the above example could be run over a 10,000 node Hadoop cluster or on a laptop without any modifications. This same code could process 20 petabytes of website text or could process a single email.
This makes the code extremely portable, which means that before shipping it can be tested on a developer’s workstation with a sample of data. The code does not need to be changed if the nature or size of the cluster changes later down the road. Also, this abstracts away all of the complexities of a distributed system for the developer, which makes his or her life easier in several ways: opportunities to make errors are reduced, fault tolerance is built in, there is lesser code to write, and so much more — in short.
Hadoop has taken off in terms of popularity owing to its accessibility to the average software developer in comparison to previous distributed computing frameworks is one of the main reasons why Hadoop has taken off in terms of popularity.

Share this on
Follow us on
- HDFS (Hadoop Distributed File System)
- YARN (Yet Another Resource Negotiator)
- MapReduce
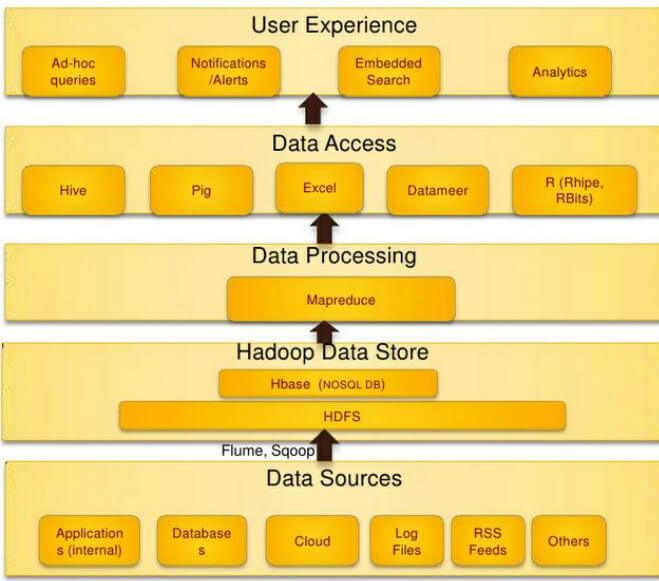 Source: data science central
Hadoop and its ecosystem represent a new way of doing things, as we’ll look at next.
Hadoop Masks Being a Distributed System
Hadoop is a distributed system, which means it coordinates the usage of a cluster of multiple computational resources (referred to as servers, computers, or nodes) that communicate over a network. Using distributed systems we can solve problems that cannot be solved by a single computer. A distributed system can store more data than can be stored on just one machine and process data much faster than a single machine can. However, this increases complexity, because the computers in the cluster need to communicate with each other, and the system needs to handle the increased chance of failure inherent in using more machines.
These are some of the disadvantages of using a distributed system. We don’t use distributed systems because we want to…we use them because we cannot do without them.
Hadoop does a good job of hiding from its users that it is a distributed system by portraying itself as a single system. This makes the life of the user a whole lot easier because he or she can focus on analysis of data part instead of manually coordinating different computers or manually planning for failures.
Take a look at this snippet of Hadoop MapReduce code written in Java. Even if you aren’t well versed with Java, you can still look at the code and get a general feel of what’s happening. There is a point to this, I promise.
Here’s an example MapReduce job that I wrote in Java to count words.
// This block of code defines the behavior of the map phase
Source: data science central
Hadoop and its ecosystem represent a new way of doing things, as we’ll look at next.
Hadoop Masks Being a Distributed System
Hadoop is a distributed system, which means it coordinates the usage of a cluster of multiple computational resources (referred to as servers, computers, or nodes) that communicate over a network. Using distributed systems we can solve problems that cannot be solved by a single computer. A distributed system can store more data than can be stored on just one machine and process data much faster than a single machine can. However, this increases complexity, because the computers in the cluster need to communicate with each other, and the system needs to handle the increased chance of failure inherent in using more machines.
These are some of the disadvantages of using a distributed system. We don’t use distributed systems because we want to…we use them because we cannot do without them.
Hadoop does a good job of hiding from its users that it is a distributed system by portraying itself as a single system. This makes the life of the user a whole lot easier because he or she can focus on analysis of data part instead of manually coordinating different computers or manually planning for failures.
Take a look at this snippet of Hadoop MapReduce code written in Java. Even if you aren’t well versed with Java, you can still look at the code and get a general feel of what’s happening. There is a point to this, I promise.
Here’s an example MapReduce job that I wrote in Java to count words.
// This block of code defines the behavior of the map phase
 // This block of code defines the behavior of the reducer phase
// This block of code defines the behavior of the reducer phase
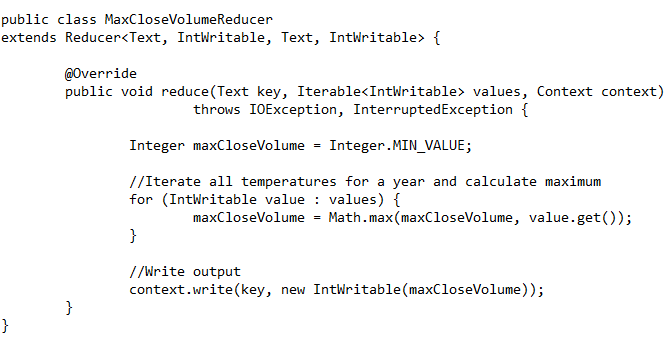 This code is for word counting, the canonical example for MapReduce. MapReduce can do all sorts of fancy things, but in this relatively simple case it takes a body of text, and it will return the list of words seen in the text along with how many times each of those words was seen.
Nowhere in the code is there a mention of how much data is being analyzed or what the size of the cluster is. . The code in the above example could be run over a 10,000 node Hadoop cluster or on a laptop without any modifications. This same code could process 20 petabytes of website text or could process a single email.
This makes the code extremely portable, which means that before shipping it can be tested on a developer’s workstation with a sample of data. The code does not need to be changed if the nature or size of the cluster changes later down the road. Also, this abstracts away all of the complexities of a distributed system for the developer, which makes his or her life easier in several ways: opportunities to make errors are reduced, fault tolerance is built in, there is lesser code to write, and so much more — in short.
Hadoop has taken off in terms of popularity owing to its accessibility to the average software developer in comparison to previous distributed computing frameworks is one of the main reasons why Hadoop has taken off in terms of popularity.
This code is for word counting, the canonical example for MapReduce. MapReduce can do all sorts of fancy things, but in this relatively simple case it takes a body of text, and it will return the list of words seen in the text along with how many times each of those words was seen.
Nowhere in the code is there a mention of how much data is being analyzed or what the size of the cluster is. . The code in the above example could be run over a 10,000 node Hadoop cluster or on a laptop without any modifications. This same code could process 20 petabytes of website text or could process a single email.
This makes the code extremely portable, which means that before shipping it can be tested on a developer’s workstation with a sample of data. The code does not need to be changed if the nature or size of the cluster changes later down the road. Also, this abstracts away all of the complexities of a distributed system for the developer, which makes his or her life easier in several ways: opportunities to make errors are reduced, fault tolerance is built in, there is lesser code to write, and so much more — in short.
Hadoop has taken off in terms of popularity owing to its accessibility to the average software developer in comparison to previous distributed computing frameworks is one of the main reasons why Hadoop has taken off in terms of popularity.
Manu Jeevan
Manu Jeevan is a self-taught data scientist and loves to explain data science concepts in simple terms. You can connect with him on LinkedIn, or email him at manu@bigdataexaminer.com.
Latest posts by Manu Jeevan (see all)
- Python IDEs for Data Science: Top 5 - January 19, 2019
- The 5 exciting machine learning, data science and big data trends for 2019 - January 19, 2019
- A/B Testing Made Simple – Part 2 - October 30, 2018
Follow us on
Free Data Science & AI Starter Course
