Edvancer's Knowledge Hub
Foundations of data science made simple (Part 3)
In the part 1 and part 2 of this series, we saw how to prepare our data set and apply machine learning algorithms to the data set. In this article, we will see how to evaluate the results of the analysis.
After building a model, it must be evaluated. Evaluation metrics are used to compare how accurate models are in their predictions. These metrics differ in how they define and penalize different types of prediction errors. Below are three evaluation metrics that are used frequently. Depending on the aims of our study, new metrics could even be designed to penalize and avoid specific types of errors.
Classification Metrics
Percentage of Correct Predictions
The most simplistic definition of prediction accuracy is the proportion of predictions that proved to be correct. Going back to our example on grocery transactions in Table A, we could express results from an example task to predict fish purchase in a statement like: Our model predicting whether a customer would buy fish was correct 90% of the time. While this metric is easy to understand, it leaves out information about where prediction errors actually occur.
Confusion Matrix
Confusion matrices provide further insight into where our prediction model succeeded and where it failed.
 Table 4. Confusion matrix showing accuracy of an example task to predict fish purchase.
Take a look at Table 4. While the model had an overall classification accuracy of 90%, it was much better at predicting non-purchases than actual purchases. We can also see that prediction errors were split equally between false positives (FP) and false negatives (FN), with five errors each.
In some situations, distinguishing the type of prediction error is crucial. A false negative in earthquake prediction (i.e. predicting no earthquake would happen but it does) would be far costlier than false positives (i.e. predicting an earthquake would happen but it does not).
Regression Metric
Root Mean Squared Error (RMSE). As regression predictions use continuous values, errors are generally quantified as the difference between predicted and actual values, with penalties varying with the magnitude of error. The root mean squared error (RMSE) is a popular regression metric, and is particularly useful in cases where we want to avoid large errors: each individual error is squared, thus amplifying large errors. This renders the RMSE extremely sensitive to outliers, of which are severely penalized.
Validation
Metrics do not give a complete picture of a model’s performance. Due to overfitting, models which fare well on a metric for current data might not do so for new data. To prevent this, we should always evaluate models using a proper validation procedure. Validation is an assessment of how accurate a model is in predicting new data. However, instead of waiting for new data to assess our model, we could split our current dataset into two parts: the first part would serve as a training dataset to generate and tune a prediction model, while the second part would act as a proxy for new data and be used as a test dataset to assess the model’s prediction accuracy. The best model is taken to be the one yielding the most accurate predictions on the test dataset. For this validation process to be effective, we should assign data points into the training and test datasets randomly and without bias.
However, if the original dataset is small, we may not have the luxury of setting aside data to form a test dataset, because we may sacrifice accuracy when the amount of data used to train our model is reduced. Hence, instead of using two separate datasets for training and testing, cross-validation would allow us to use one dataset for both purposes.
Cross-validation maximizes the availability of data for validation by dividing the dataset into several segments that are used to test the model repeatedly. In a single iteration, all but one of the segments would be used to train a predictive model, which is then tested on the last segment. This process is repeated until each segment has been used as the test segment exactly once (see the below figure3).
Figure 3. Cross-validation of a dataset. The dataset has been divided into four segments, and the final prediction accuracy is the average of the four results.
As different segments are used to generate predictions for each iteration, the resulting predictions would vary. By accounting for such variations, we can achieve a more robust estimate of a model’s actual predictive ability. The final estimate of a model’s accuracy is taken as the average of that across all iterations. If results from cross-validation suggest that our model’s prediction accuracy is low, we can go back to re-tune the parameters or re-process the data.
To conclude,
There are four key steps in a data science study:
Table 4. Confusion matrix showing accuracy of an example task to predict fish purchase.
Take a look at Table 4. While the model had an overall classification accuracy of 90%, it was much better at predicting non-purchases than actual purchases. We can also see that prediction errors were split equally between false positives (FP) and false negatives (FN), with five errors each.
In some situations, distinguishing the type of prediction error is crucial. A false negative in earthquake prediction (i.e. predicting no earthquake would happen but it does) would be far costlier than false positives (i.e. predicting an earthquake would happen but it does not).
Regression Metric
Root Mean Squared Error (RMSE). As regression predictions use continuous values, errors are generally quantified as the difference between predicted and actual values, with penalties varying with the magnitude of error. The root mean squared error (RMSE) is a popular regression metric, and is particularly useful in cases where we want to avoid large errors: each individual error is squared, thus amplifying large errors. This renders the RMSE extremely sensitive to outliers, of which are severely penalized.
Validation
Metrics do not give a complete picture of a model’s performance. Due to overfitting, models which fare well on a metric for current data might not do so for new data. To prevent this, we should always evaluate models using a proper validation procedure. Validation is an assessment of how accurate a model is in predicting new data. However, instead of waiting for new data to assess our model, we could split our current dataset into two parts: the first part would serve as a training dataset to generate and tune a prediction model, while the second part would act as a proxy for new data and be used as a test dataset to assess the model’s prediction accuracy. The best model is taken to be the one yielding the most accurate predictions on the test dataset. For this validation process to be effective, we should assign data points into the training and test datasets randomly and without bias.
However, if the original dataset is small, we may not have the luxury of setting aside data to form a test dataset, because we may sacrifice accuracy when the amount of data used to train our model is reduced. Hence, instead of using two separate datasets for training and testing, cross-validation would allow us to use one dataset for both purposes.
Cross-validation maximizes the availability of data for validation by dividing the dataset into several segments that are used to test the model repeatedly. In a single iteration, all but one of the segments would be used to train a predictive model, which is then tested on the last segment. This process is repeated until each segment has been used as the test segment exactly once (see the below figure3).
Figure 3. Cross-validation of a dataset. The dataset has been divided into four segments, and the final prediction accuracy is the average of the four results.
As different segments are used to generate predictions for each iteration, the resulting predictions would vary. By accounting for such variations, we can achieve a more robust estimate of a model’s actual predictive ability. The final estimate of a model’s accuracy is taken as the average of that across all iterations. If results from cross-validation suggest that our model’s prediction accuracy is low, we can go back to re-tune the parameters or re-process the data.
To conclude,
There are four key steps in a data science study:

Share this on
Follow us on
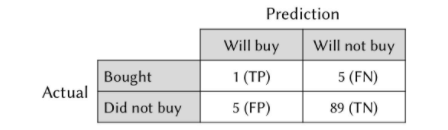 Table 4. Confusion matrix showing accuracy of an example task to predict fish purchase.
Take a look at Table 4. While the model had an overall classification accuracy of 90%, it was much better at predicting non-purchases than actual purchases. We can also see that prediction errors were split equally between false positives (FP) and false negatives (FN), with five errors each.
In some situations, distinguishing the type of prediction error is crucial. A false negative in earthquake prediction (i.e. predicting no earthquake would happen but it does) would be far costlier than false positives (i.e. predicting an earthquake would happen but it does not).
Regression Metric
Root Mean Squared Error (RMSE). As regression predictions use continuous values, errors are generally quantified as the difference between predicted and actual values, with penalties varying with the magnitude of error. The root mean squared error (RMSE) is a popular regression metric, and is particularly useful in cases where we want to avoid large errors: each individual error is squared, thus amplifying large errors. This renders the RMSE extremely sensitive to outliers, of which are severely penalized.
Validation
Metrics do not give a complete picture of a model’s performance. Due to overfitting, models which fare well on a metric for current data might not do so for new data. To prevent this, we should always evaluate models using a proper validation procedure. Validation is an assessment of how accurate a model is in predicting new data. However, instead of waiting for new data to assess our model, we could split our current dataset into two parts: the first part would serve as a training dataset to generate and tune a prediction model, while the second part would act as a proxy for new data and be used as a test dataset to assess the model’s prediction accuracy. The best model is taken to be the one yielding the most accurate predictions on the test dataset. For this validation process to be effective, we should assign data points into the training and test datasets randomly and without bias.
However, if the original dataset is small, we may not have the luxury of setting aside data to form a test dataset, because we may sacrifice accuracy when the amount of data used to train our model is reduced. Hence, instead of using two separate datasets for training and testing, cross-validation would allow us to use one dataset for both purposes.
Cross-validation maximizes the availability of data for validation by dividing the dataset into several segments that are used to test the model repeatedly. In a single iteration, all but one of the segments would be used to train a predictive model, which is then tested on the last segment. This process is repeated until each segment has been used as the test segment exactly once (see the below figure3).
Table 4. Confusion matrix showing accuracy of an example task to predict fish purchase.
Take a look at Table 4. While the model had an overall classification accuracy of 90%, it was much better at predicting non-purchases than actual purchases. We can also see that prediction errors were split equally between false positives (FP) and false negatives (FN), with five errors each.
In some situations, distinguishing the type of prediction error is crucial. A false negative in earthquake prediction (i.e. predicting no earthquake would happen but it does) would be far costlier than false positives (i.e. predicting an earthquake would happen but it does not).
Regression Metric
Root Mean Squared Error (RMSE). As regression predictions use continuous values, errors are generally quantified as the difference between predicted and actual values, with penalties varying with the magnitude of error. The root mean squared error (RMSE) is a popular regression metric, and is particularly useful in cases where we want to avoid large errors: each individual error is squared, thus amplifying large errors. This renders the RMSE extremely sensitive to outliers, of which are severely penalized.
Validation
Metrics do not give a complete picture of a model’s performance. Due to overfitting, models which fare well on a metric for current data might not do so for new data. To prevent this, we should always evaluate models using a proper validation procedure. Validation is an assessment of how accurate a model is in predicting new data. However, instead of waiting for new data to assess our model, we could split our current dataset into two parts: the first part would serve as a training dataset to generate and tune a prediction model, while the second part would act as a proxy for new data and be used as a test dataset to assess the model’s prediction accuracy. The best model is taken to be the one yielding the most accurate predictions on the test dataset. For this validation process to be effective, we should assign data points into the training and test datasets randomly and without bias.
However, if the original dataset is small, we may not have the luxury of setting aside data to form a test dataset, because we may sacrifice accuracy when the amount of data used to train our model is reduced. Hence, instead of using two separate datasets for training and testing, cross-validation would allow us to use one dataset for both purposes.
Cross-validation maximizes the availability of data for validation by dividing the dataset into several segments that are used to test the model repeatedly. In a single iteration, all but one of the segments would be used to train a predictive model, which is then tested on the last segment. This process is repeated until each segment has been used as the test segment exactly once (see the below figure3).
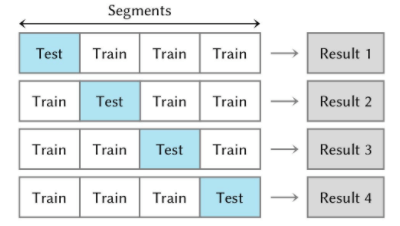 Figure 3. Cross-validation of a dataset. The dataset has been divided into four segments, and the final prediction accuracy is the average of the four results.
As different segments are used to generate predictions for each iteration, the resulting predictions would vary. By accounting for such variations, we can achieve a more robust estimate of a model’s actual predictive ability. The final estimate of a model’s accuracy is taken as the average of that across all iterations. If results from cross-validation suggest that our model’s prediction accuracy is low, we can go back to re-tune the parameters or re-process the data.
To conclude,
There are four key steps in a data science study:
Figure 3. Cross-validation of a dataset. The dataset has been divided into four segments, and the final prediction accuracy is the average of the four results.
As different segments are used to generate predictions for each iteration, the resulting predictions would vary. By accounting for such variations, we can achieve a more robust estimate of a model’s actual predictive ability. The final estimate of a model’s accuracy is taken as the average of that across all iterations. If results from cross-validation suggest that our model’s prediction accuracy is low, we can go back to re-tune the parameters or re-process the data.
To conclude,
There are four key steps in a data science study:
- Prepare data
- Select algorithms to model the data
- Tune algorithms to optimize the models
- Evaluate the models based on their accuracy
Manu Jeevan
Manu Jeevan is a self-taught data scientist and loves to explain data science concepts in simple terms. You can connect with him on LinkedIn, or email him at manu@bigdataexaminer.com.
Latest posts by Manu Jeevan (see all)
- Python IDEs for Data Science: Top 5 - January 19, 2019
- The 5 exciting machine learning, data science and big data trends for 2019 - January 19, 2019
- A/B Testing Made Simple – Part 2 - October 30, 2018
Follow us on
Free Data Science & AI Starter Course
