Edvancer's Knowledge Hub
How does a data scientist use programming – part 1

Data scientists need software engineering skills—just not all of them. By “professional” data science programmers, I mean data scientists with essential data product engineering skills. Professionalism isn’t something you can own like a certification or hours of experience; I’m talking about professionalism as an approach. The professional data science programmers have general strategies for recognizing where their work sucks and correcting the problem. They are, in a sense, self-correcting.
The professional data science programmer has to turn a hypothesis into software capable of testing that hypothesis. Due to the types of problems faced by data scientists, data science programming is a unique branch of software engineering. The big challenge is that the nature of data science is experimental with often difficult challenges and messy data. For a lot of these problems, there is no fixed strategy to obtain a solution and possible solutions are usually achieved through small steps. In what follows, I describe general strategies for a disciplined, productive trial-and-error process: breaking problems into small steps, trying solutions, and making corrections along the way.
Think Like a Pro
To be a professional data science programmer, you need to know more than the structures of the system. You have to know how to design a solution, have the ability to foresee a possible solution, and be able to recognize when you don’t fully understand it. Having a deep understanding of your solution is essential to being self-correcting.
When you understand the conceptual gaps in your approach, it is easier to fill them in yourself. To design a data science solution in a way that you can be self-correcting, I’ve found it useful to
follow the basic process of look, see, imagine, and show.
Step 1: Look
First step, scan the environment. Do background research and get acquainted with all the pieces that might be related to the problem you are trying to solve. Look at your problem as broadly as you can. Get an insight into your situation as well as you can and gather disparate pieces of information.
Step 2: See
Take the disparate pieces you discovered and just somehow bunch them up into abstractions that correspond to elements of the blackboard pattern. At this stage, you are giving birth to meaningful, technical concepts from elements of the problem. Seeing the problem is a critical step for laying the foundations for creating a viable design.
Step 3: Imagine
Imagine some implementation that moves you from the present to your target state using the technical concepts you see. If you can’t imagine an implementation, then you probably overlooked something when you looked at the problem.
Step 4: Show
Explain your solution first to yourself, then to a peer, then to your boss, and finally to a target user. Nothing too elaborate, just formal enough to be clear and precise: a water-cooler conversation, an email, a 15-minute walk through.
This is the most imperative regular practice in becoming a self-correcting professional data science programmer. If there are any gaps in your approach, they’ll most likely surface when you try to explain it. Take the time to fill in the gaps and make sure you can properly explain the problem and its solution.
Designs Like a Pro
There is a lot of variety and complexity in the activities of creating and releasing a data product, but, typically, what you do will fall somewhere in what Alistair Croll describes as the big-data supply chain.
Because data products execute according to a paradigm (real time, batch mode, or some hybrid of the two), you will likely find yourself having to deal with a combination of data supply chain activity and a data-product paradigm: ingesting and cleaning batch-updated data, making an algorithm to analyze real-time data, sharing the results of a batch process, etc. Fortunately, the blackboard architectural pattern gives us a basic blueprint for good software engineering in each one of these scenarios.
 According to the blackboard pattern we should divide the overall task of finding a solution into a set of smaller, self-contained subtasks. Each subtask turns into a hypothesis that’s easier to solve or a hypothesis whose solution is already known. Each task gradually improves the solution and leads, hopefully, to a viable resolution.
Data science is abundant in tools, each with their own unique virtues. Productivity is a big deal, and I like letting my team choose whatever tools they are most familiar with. Using the blackboard pattern makes it easier to use these different technologies collectively to build data products. Cooperation between algorithms happens through a shared repository. Each algorithm has access to data to process it as input and provide the results back so that some other algorithm may have access to it.
Last, the algorithms are all coordinated using a single control component that represents the heuristic used to solve the problem. The strategy you’ve chosen to solve the problem is implemented by the control. This is the ultimate level of abstraction and understanding of the problem, and it’s implemented by a technology that can interface with and determine the order of all the other algorithms- something automated like a Cron job or a script can be the control. Or it can be manual, like a person that executes the various steps in the proper order. But overall, it’s the total strategy for solving the problem. You can see the solution to the problem from beginning to end only in this place.
This basic approach has proven useful in constructing software systems that have to solve hypothetical problems using incomplete data which are uncertain. The best part is that it lets us make progress with an uncertain problem using certain, deterministic pieces. Unfortunately, hard work paying off can’t be guaranteed in this case. It’s better to know sooner rather than later if you are going down a path that won’t work. You do this using the order in which you implement the system.
According to the blackboard pattern we should divide the overall task of finding a solution into a set of smaller, self-contained subtasks. Each subtask turns into a hypothesis that’s easier to solve or a hypothesis whose solution is already known. Each task gradually improves the solution and leads, hopefully, to a viable resolution.
Data science is abundant in tools, each with their own unique virtues. Productivity is a big deal, and I like letting my team choose whatever tools they are most familiar with. Using the blackboard pattern makes it easier to use these different technologies collectively to build data products. Cooperation between algorithms happens through a shared repository. Each algorithm has access to data to process it as input and provide the results back so that some other algorithm may have access to it.
Last, the algorithms are all coordinated using a single control component that represents the heuristic used to solve the problem. The strategy you’ve chosen to solve the problem is implemented by the control. This is the ultimate level of abstraction and understanding of the problem, and it’s implemented by a technology that can interface with and determine the order of all the other algorithms- something automated like a Cron job or a script can be the control. Or it can be manual, like a person that executes the various steps in the proper order. But overall, it’s the total strategy for solving the problem. You can see the solution to the problem from beginning to end only in this place.
This basic approach has proven useful in constructing software systems that have to solve hypothetical problems using incomplete data which are uncertain. The best part is that it lets us make progress with an uncertain problem using certain, deterministic pieces. Unfortunately, hard work paying off can’t be guaranteed in this case. It’s better to know sooner rather than later if you are going down a path that won’t work. You do this using the order in which you implement the system.

Share this on
Follow us on
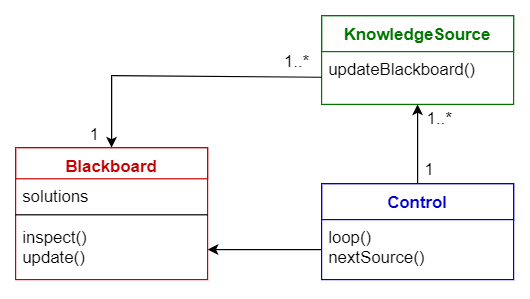 According to the blackboard pattern we should divide the overall task of finding a solution into a set of smaller, self-contained subtasks. Each subtask turns into a hypothesis that’s easier to solve or a hypothesis whose solution is already known. Each task gradually improves the solution and leads, hopefully, to a viable resolution.
Data science is abundant in tools, each with their own unique virtues. Productivity is a big deal, and I like letting my team choose whatever tools they are most familiar with. Using the blackboard pattern makes it easier to use these different technologies collectively to build data products. Cooperation between algorithms happens through a shared repository. Each algorithm has access to data to process it as input and provide the results back so that some other algorithm may have access to it.
Last, the algorithms are all coordinated using a single control component that represents the heuristic used to solve the problem. The strategy you’ve chosen to solve the problem is implemented by the control. This is the ultimate level of abstraction and understanding of the problem, and it’s implemented by a technology that can interface with and determine the order of all the other algorithms- something automated like a Cron job or a script can be the control. Or it can be manual, like a person that executes the various steps in the proper order. But overall, it’s the total strategy for solving the problem. You can see the solution to the problem from beginning to end only in this place.
This basic approach has proven useful in constructing software systems that have to solve hypothetical problems using incomplete data which are uncertain. The best part is that it lets us make progress with an uncertain problem using certain, deterministic pieces. Unfortunately, hard work paying off can’t be guaranteed in this case. It’s better to know sooner rather than later if you are going down a path that won’t work. You do this using the order in which you implement the system.
According to the blackboard pattern we should divide the overall task of finding a solution into a set of smaller, self-contained subtasks. Each subtask turns into a hypothesis that’s easier to solve or a hypothesis whose solution is already known. Each task gradually improves the solution and leads, hopefully, to a viable resolution.
Data science is abundant in tools, each with their own unique virtues. Productivity is a big deal, and I like letting my team choose whatever tools they are most familiar with. Using the blackboard pattern makes it easier to use these different technologies collectively to build data products. Cooperation between algorithms happens through a shared repository. Each algorithm has access to data to process it as input and provide the results back so that some other algorithm may have access to it.
Last, the algorithms are all coordinated using a single control component that represents the heuristic used to solve the problem. The strategy you’ve chosen to solve the problem is implemented by the control. This is the ultimate level of abstraction and understanding of the problem, and it’s implemented by a technology that can interface with and determine the order of all the other algorithms- something automated like a Cron job or a script can be the control. Or it can be manual, like a person that executes the various steps in the proper order. But overall, it’s the total strategy for solving the problem. You can see the solution to the problem from beginning to end only in this place.
This basic approach has proven useful in constructing software systems that have to solve hypothetical problems using incomplete data which are uncertain. The best part is that it lets us make progress with an uncertain problem using certain, deterministic pieces. Unfortunately, hard work paying off can’t be guaranteed in this case. It’s better to know sooner rather than later if you are going down a path that won’t work. You do this using the order in which you implement the system.
Manu Jeevan
Manu Jeevan is a self-taught data scientist and loves to explain data science concepts in simple terms. You can connect with him on LinkedIn, or email him at manu@bigdataexaminer.com.
Latest posts by Manu Jeevan (see all)
- Python IDEs for Data Science: Top 5 - January 19, 2019
- The 5 exciting machine learning, data science and big data trends for 2019 - January 19, 2019
- A/B Testing Made Simple – Part 2 - October 30, 2018
Follow us on
Free Data Science & AI Starter Course
