Edvancer's Knowledge Hub
Top 4 ways to encode categorical variables
So far, we have explored the data using various descriptive statistics techniques and also dealt with missing values and outliers. It may seem that we are done with all the data pre-processing and preparation, and ready to apply one of the ML algorithms. Unfortunately, we are still far from simply applying any ML algorithm. Wondering what it is now, it is the categorical variables.
Why even bother!!
A real-world data set would have a mix of continuous and categorical variables. Many ML algorithms like tree-based methods can inherently deal with categorical variables. However, algebraic algorithms like linear/logistic regression, SVM, KNN take only numerical features as input. Hence, categorical features need to be encoded to numerical values.
Nominal and Ordinal categories
Categorical variables can possibly take on a limited number of values. For example, T-shirt size could have these possible levels – Extra Small, Small, Medium, Large, Extra Large. T-shirts could come in a variety of colors like red, blue, yellow and so on. Or, a dataset about information related to users would have categorical features like country, gender, age group, education level among other continuous features.
Categorical features can be broadly classified as nominal and ordinal variables. In the T-shirt example above, the sizes can be ordered as XL > L > M > S > XS. Such variables which can be sorted or ordered are called Ordinal variables. In the same T-shirt example, colors form what is known as Nominal variable. A nominal variable has multiple levels or categories without any intrinsic ordering to them.
We will discuss ways to encode ordinal and nominal variables into numerical variables typically used in machine learning applications
 Here the numerical labels assigned to the outcome levels can be misinterpreted by the algorithm. A learning algorithm would assume that Transfer is larger than Adoption, and so on.
The better solutions for this problem is to use OneHot encoding or Dummy encoding technique.
One hot encoding performs better when the category cardinality of a feature is not too high. Because for feature with high cardinality, one hot encoding would create a large number of columns which could lead to memory problems.
Binary encoding is good for high cardinality data as it creates very few new columns. Most similar values overlap with each other across many of the new columns. This allows many machine learning algorithms to learn the similarity of the values.
Here the numerical labels assigned to the outcome levels can be misinterpreted by the algorithm. A learning algorithm would assume that Transfer is larger than Adoption, and so on.
The better solutions for this problem is to use OneHot encoding or Dummy encoding technique.
One hot encoding performs better when the category cardinality of a feature is not too high. Because for feature with high cardinality, one hot encoding would create a large number of columns which could lead to memory problems.
Binary encoding is good for high cardinality data as it creates very few new columns. Most similar values overlap with each other across many of the new columns. This allows many machine learning algorithms to learn the similarity of the values.
Share this on
Follow us on
How to identify the Categorical Data
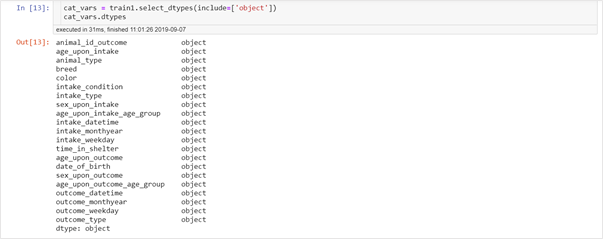
We saw how to graphically analyse the categorical variables in one of my previous articles. To revise, Bar chart, pie chart and box plots can be used to visualise the categorical variables.Identifying the categorical variables, features with type as object are categorical variables
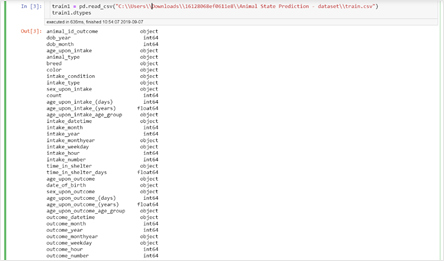
Dataframe cat_vars has all the categorical variables
Encoding techniques
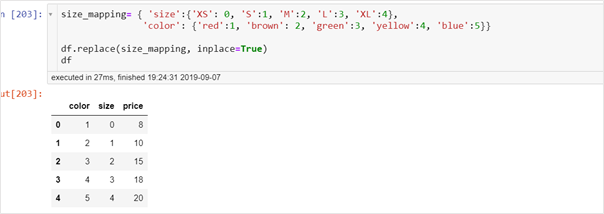
1. Replace or Custom Mapping
This encoding is particularly useful for ordinal variable where the order of categories is important. To make sure that the learning algorithm interprets the ordinal variables correctly, we can map the categorical values to integer values manually. There are two ways to do so – one is to use map function and another is to use replace function.We could encode the T-shirt size using map function as:
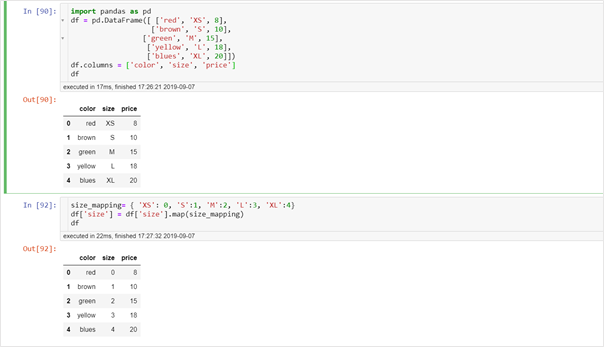
We could encode the T-shirt size using replace function as:
2. Label Encoding
Label encoders transform non-numerical labels into numerical labels. Each category is assigned a unique label starting from 0 and going on till n_categories – 1 per feature. Label encoders are suitable for encoding variables where alphabetical alignment or numerical value of labels is important. However, if you got nominal data, using label encoders may not be such a good idea. For instance,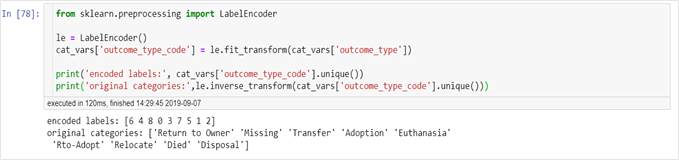 Here the numerical labels assigned to the outcome levels can be misinterpreted by the algorithm. A learning algorithm would assume that Transfer is larger than Adoption, and so on.
The better solutions for this problem is to use OneHot encoding or Dummy encoding technique.
Here the numerical labels assigned to the outcome levels can be misinterpreted by the algorithm. A learning algorithm would assume that Transfer is larger than Adoption, and so on.
The better solutions for this problem is to use OneHot encoding or Dummy encoding technique.
3. OneHot encoding
One-hot encoding is the most widely used encoding scheme. It works by creating a column for each category present in the feature and assigning a 1 or 0 to indicate the presence of a category in the data. For example,One hot encoding using Pandas
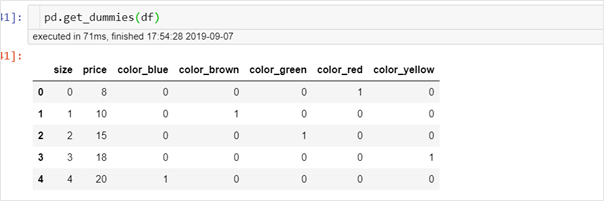
A separate column is created for each possible value. A value of 1 in a column represents the presence of that level in the original data.
Pandas get_dummies method can be applied to a data frame and will only convert string columns into numbers and leave all others as it is. An alternative to get_dummies method is sklearn’s OneHotEncoder and LabelBinarizer functions which return an array. This data frame should be concatenated with the original data frame as shown below.One hot encoding using scikit’s LabelBinarizer
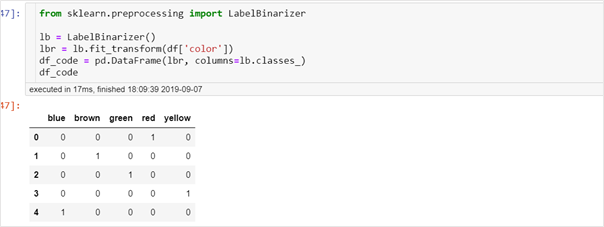
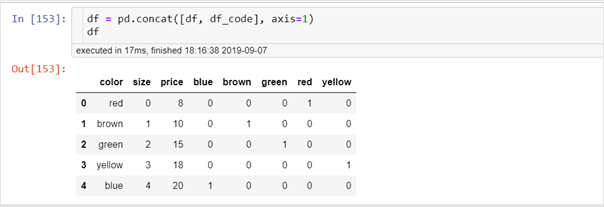 One hot encoding performs better when the category cardinality of a feature is not too high. Because for feature with high cardinality, one hot encoding would create a large number of columns which could lead to memory problems.
One hot encoding performs better when the category cardinality of a feature is not too high. Because for feature with high cardinality, one hot encoding would create a large number of columns which could lead to memory problems.
4. Binary encoding
Binary encoding is not as intuitive as the above two approaches. Binary encoding works like this:- The categories are encoded as ordinal, for example, categories like red, yellow, green are assigned labels as 1, 2, 3 (let’s assume).
- These integers are then converted into binary code, so for example 1 becomes 001 and 2 becomes 010 and so on.
- Then the digits from that binary string are split into separate columns.
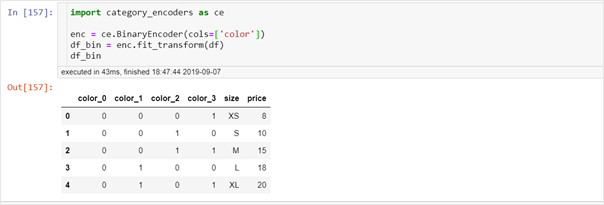 Binary encoding is good for high cardinality data as it creates very few new columns. Most similar values overlap with each other across many of the new columns. This allows many machine learning algorithms to learn the similarity of the values.
Binary encoding is good for high cardinality data as it creates very few new columns. Most similar values overlap with each other across many of the new columns. This allows many machine learning algorithms to learn the similarity of the values.
Contrast Encoders
Above are the type of classic encoding techniques used widespread in machine learning projects. There are available advanced encoders called contrast encoders. Contrast encoders work by comparing the mean of the independent and dependent variables over their levels. Never worked on these techniques, but here is a brief overview of these encoders: Sum: Sum coding compares the mean of the dependent variable for a given level to the overall mean of the dependent variable over all the levels. That is, it uses contrasts between each of the first k-1 levels and level k. In this example, level 1 is compared to all the others, level 2 to all the others, and level 3 to all the others. Backward Difference Coding: In backward difference coding, the mean of the dependent variable for a level is compared with the mean of the dependent variable for the prior level. This type of coding may be useful for a nominal or an ordinal variable. Helmert Coding: The mean of the dependent variable for a level is compared to the mean of the dependent variable over all previous levels. Hence, the name ‘reverse’ is sometimes applied to differentiate from forward Helmert coding. Orthogonal Polynomial Coding: The coefficients taken on by polynomial coding for k=4 levels are the linear, quadratic, and cubic trends in the categorical variable. The categorical variable here is assumed to be represented by an underlying, equally spaced numeric variable. Therefore, this type of encoding is used only for ordered categorical variables with equal spacing. In general, the polynomial contrast produces polynomials of order k-1. Worried about which technique to use for your task. Well, there is no fixed answer to that. Try out various techniques and find out which one suits your data the best. Category Encoders is a python library for encoding categorical variables into numeric by means of different techniques. This library supports all the techniques mentioned above as well as Bayesian encoders. Read more about it at https://contrib.scikit-learn.org/categorical-encoding/ Hope you find this article useful. Share your feedback/comments/insights on categorical variable encoding. References: https://towardsdatascience.com/smarter-ways-to-encode-categorical-data-for-machine-learning-part-1-of-3-6dca2f71b159 http://www.statsmodels.org/dev/contrasts.htmlLatest posts by Yogita Kinha (see all)
- A simple guide to Hypothesis Testing - September 24, 2019
- Accelerate your job search with Word cloud in Python - September 22, 2019
- AI revolution in Healthcare industry - September 8, 2019
Follow us on
Free Data Science & AI Starter Course
